Scalable AI Solutions That Accelerate Enterprise-Wide Deployment Success

Summary:
Every entrepreneur or solopreneur dreams of taking advantage of artificial intelligence to automate processes, uncover insights, and outperform competition.
Yet, most AI projects never make it beyond the lab.
This is where scalable AI solutions come into play, designed to transform isolated models into production-grade, enterprise-scale AI systems that adapt dynamically, handle massive workloads, and drive continuous ROI.
Whether you’re an early-stage founder building on limited compute resources or a healthcare enterprise managing petabytes of patient data, scalable artificial intelligence systems offer the architectural backbone to deliver results at scale, in real time, and on budget.
In this blog, we’ll unpack what enterprises can learn from startups that successfully deployed scalable machine learning solutions and how the next generation of distributed AI systems is shaping the landscape of enterprise-wide deployment success.
So, give it a thorough read now.
Key Takeaways
- Scalable AI solutions are the foundation for sustainable digital transformation.
- They enable real-time inference, automated scaling, and reliable governance across departments.
- Case studies show measurable ROI, faster deployments, higher accuracy, and cost savings.
- The future of scalable AI architecture will blend edge computing, MLOps, and autonomous orchestration.
- Entrepreneurs who adopt scalable AI platforms early will future-proof their business for exponential growth.
The Need for Scalability: Beyond One-Off AI Wins
It is not just about running bigger models but creating sustainable, adaptable, and fault-tolerant systems that evolve as data grows.
Imagine deploying a chatbot that handles 1,000 queries a day, then suddenly needs to serve 100,000 as your startup goes viral.
Without a scalable AI infrastructure, your once-efficient model crashes under pressure.
Scalable AI solutions solve this through:
- Elastic resource allocation: Using cloud-native autoscaling (AWS, Azure, or GCP) to match computational demand dynamically.
- Horizontal and vertical scaling: Expanding compute nodes or upgrading GPU/TPU cores to maintain real-time inference speeds.
- Fault tolerance: Ensuring no downtime during retraining, deployment, or updates.
| Outcome: A scalable AI deployment pipeline that grows effortlessly with your business, ensuring consistent performance from startup MVPs to enterprise workloads. |
The Architecture of Scalable AI Systems
To scale AI successfully, you need the right architecture, an intelligent ecosystem that balances speed, flexibility, and reliability.
Core Components of a Scalable AI Architecture
Data Engineering Layer
- Ingestion: Streaming or batch data collected through APIs or sensors.
- Processing: ETL pipelines ensure clean, structured data.
- Storage: Distributed databases and object storage (e.g., Snowflake, BigQuery, S3).
Model Development Layer
- Modular model design using frameworks like TensorFlow, PyTorch, or ONNX.
- Reusable model architectures for transfer learning and rapid experimentation.
- Experiment tracking via MLflow or Weights & Biases.
Training & Orchestration
- Distributed training on clusters (using Ray, Horovod).
- Autoscaling compute nodes for optimal resource utilization.
- Integration with AIOps / MLOps pipelines for version control and CI/CD automation.
Model Serving & Inference
- Microservices-based serving (TensorFlow Serving, TorchServe).
- Load balancing and real-time scalable AI inference with GPUs/TPUs.
- Low latency is achieved via caching, batching, and sharding.
Monitoring & Governance
- Model performance tracking (drift detection, bias monitoring).
- Data lineage and governance tools (e.g., Great Expectations, Monte Carlo).
- Security protocols (ISO/IEC 27001, NIST AI framework).
Insight: A scalable AI pipeline built on this architecture ensures that from training to serving, every step is automated, monitored, and resilient.
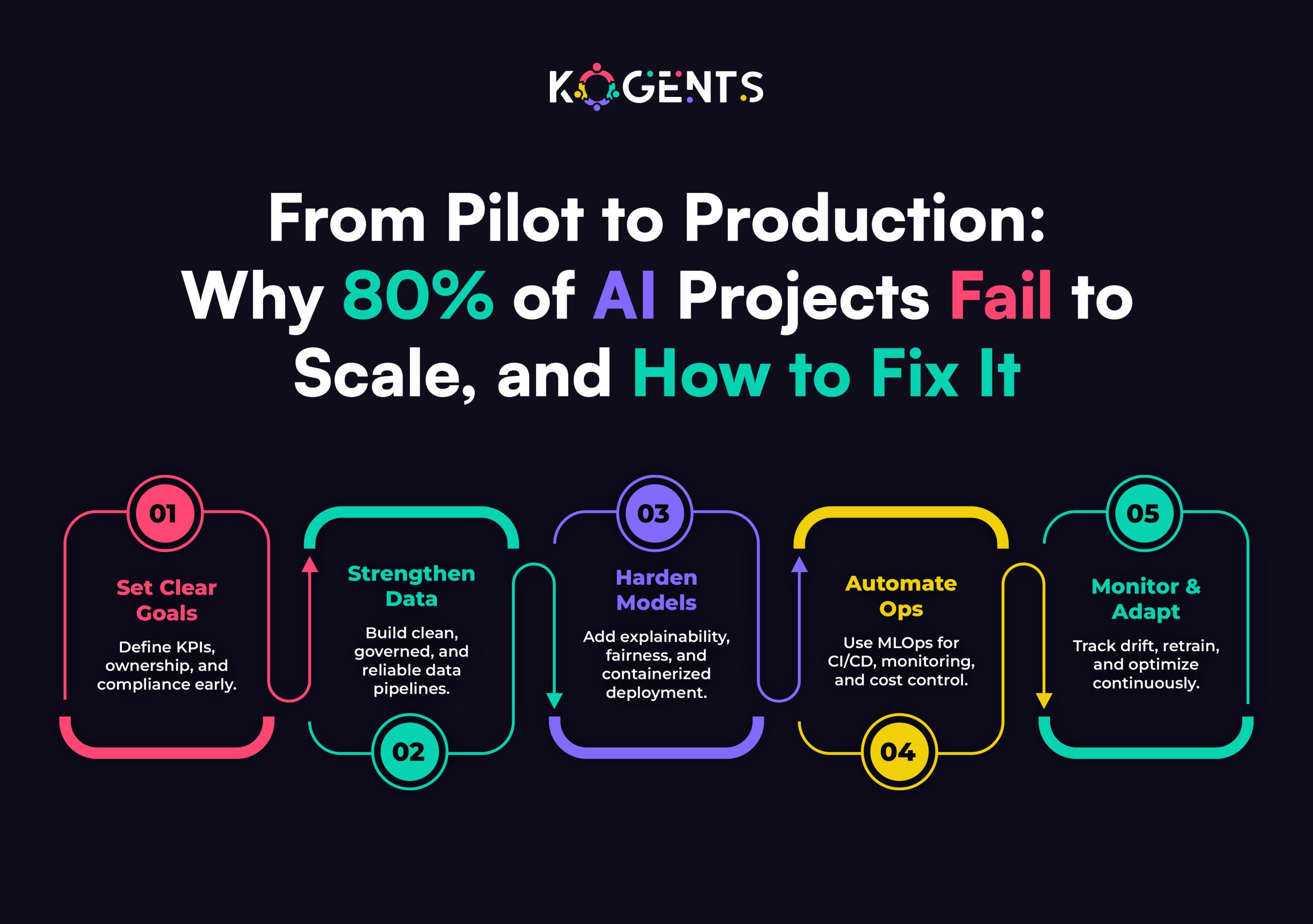
Common Challenges and Limitations in Scaling AI
Building an AI model is easy, but scaling it efficiently? That’s where most organizations stumble.
Here are the key limitations that hinder enterprise AI development and deployment.
- Data fragmentation: Siloed or inconsistent data pipelines disrupt training and inference flow.
- Infrastructure overhead: GPUs and high-performance hardware inflate costs without smart orchestration.
- Model drift: AI systems degrade over time as real-world data diverges from training sets.
- Latency and throughput bottlenecks: Without scalable inference systems, predictions lag during high traffic.
- Governance and compliance: Scaling AI across departments introduces new privacy, ethics, and data governance challenges.
| For solopreneurs, that might mean integrating lightweight, scalable AI frameworks like FastAPI + PyTorch Lightning; for enterprises, it involves multi-cloud orchestration using Kubernetes or Kubeflow pipelines. |
AI Agents vs. Other Tools
| Feature | AI Agents (Scalable AI Solutions) | Traditional Automation Tools | Manual Operations |
| Learning Capability | Continuously improves via ML/DL | Static, predefined rules | Human-dependent |
| Scalability | Built on a scalable AI architecture with autoscaling | Limited by server capacity | None |
| Deployment Speed | Instant via containerized deployment | Requires manual setup | N/A |
| Adaptability | Context-aware and data-driven | Fixed logic | Human flexibility only |
| Cost Efficiency | Pay-per-use on cloud, optimized compute | License or hardware-heavy | Labor cost-intensive |
| Accuracy Over Time | Increases via retraining and feedback loops | Declines without updates | Inconsistent |
| Use Case Fit | Perfect for enterprise-scale AI apps | Simple automations | Creative or ad-hoc tasks |
Case Study Spotlight: Scaling AI in Action
Case Study 1: E-commerce Optimization at Scale
A mid-sized retailer struggled to forecast demand across 10,000 SKUs, by deploying a scalable machine learning solution on Google Cloud Vertex AI, the company automated inventory management.
- Result: Forecast accuracy improved by 37%, while cloud costs dropped by 28% due to autoscaling and real-time inference.
Case Study 2: Healthcare Triage with Scalable AI Systems
A telemedicine startup built an AI at scale triage system using federated learning to preserve data privacy across hospitals.
- Result: Patient routing efficiency increased by 60%, while maintaining HIPAA compliance.
Case Study 3: Solopreneur AI Content Platform
A single-founder business integrated scalable AI deployment pipelines on AWS Lambda for content personalization.
- Result: Reduced content generation time from hours to minutes, saving 20 hours weekly.
Note: These examples demonstrate that scalable AI infrastructure is not just for big tech; it’s the democratizing layer that allows anyone to deploy intelligence at enterprise-grade scale.
Enablers of Successful Enterprise-Wide AI Deployment
Scaling AI is not just about technology but about strategy, governance, and the alignment of people, processes, and infrastructure. This approach is exemplified by the best agentic AI company in the enterprise industry.
Organizations that succeed with scalable AI solutions share a few core enablers that distinguish them from those perpetually stuck in pilot mode.
1. Unified Data Foundation
The backbone of any scalable AI architecture is a unified, governed, and high-quality data ecosystem.
- Data integration and governance: Enterprises must establish robust data pipelines and metadata tracking for every source, ensuring consistency, compliance, and lineage.
- Example: IBM’s “AI Readiness Framework” emphasizes that data accessibility and standardization are the first checkpoints in scaling AI effectively.
2. Modular and Elastic Infrastructure
Modern AI scalability depends on infrastructure that grows and shrinks on demand.
- Cloud-native, containerized environments like Kubernetes and Docker ensure models are portable across clusters and clouds.
- Elastic AI systems leverage horizontal and vertical scaling in AI, allocating GPUs/TPUs dynamically to balance cost and performance.
Case Insight: A report from McKinsey claims that organizations must move from AI experimentation to industrialized scalability, designing systems that anticipate integration, monitoring, and cost control. Unlike traditional IT, gen AI’s recurring costs can exceed initial build costs, making economic sustainability essential.
3. Cross-Functional AI Operating Model
Technology alone doesn’t scale; teams do.
- A centralized AI Center of Excellence (CoE) with data scientists, domain experts, and ML engineers accelerates reuse and governance.
- MLOps and AIOps practices streamline model delivery, automating retraining, drift detection, and rollout across departments.
- Continuous Monitoring and Optimization
Scalable AI deployment doesn’t end at launch.
- Enterprises must track model performance, drift, and bias in production to ensure fair, accurate predictions.
- Real-time scalable AI pipelines with built-in observability tools (like Prometheus or Grafana) help sustain reliability under unpredictable workloads.
5. Compliance, Security, and Trust
As models scale, so does their ethical and regulatory footprint.
- Ensure adherence to frameworks such as ISO/IEC 27001, NIST AI RMF, and emerging EU AI Act standards.
- Apply explainability tools (e.g., SHAP, LIME) to maintain transparency and stakeholder confidence.
| The GenAI Divide is starkest in deployment rates; only 5% of custom enterprise AI tools reach production. |

Conclusion
The age of scalable AI solutions is here, and it’s redefining what’s possible for businesses of every size.
Whether you’re an emerging entrepreneur, a healthcare innovator, or an enterprise CTO, the ability to deploy and scale AI seamlessly determines how quickly you can innovate, compete, and grow.
Scalable artificial intelligence systems ensure that your ideas don’t stay in the lab; they evolve into production-ready models that learn, adapt, and thrive in dynamic business environments.
At its heart, scalability isn’t just a technical choice; it’s a growth philosophy. It’s about building AI that grows with you, intelligently, efficiently, and ethically.
But, are you ready to accelerate your AI journey?
Then have a look at how Kogents deploys scalable AI effortlessly.
FAQs
What are scalable AI solutions?
Scalable AI solutions are systems engineered to maintain performance as workloads and data volumes grow. They use cloud computing, distributed architectures, and MLOps to deliver high-performance AI systems capable of serving thousands, or millions, of users simultaneously.
How do scalable AI architectures differ from traditional AI setups?
Traditional setups are static and local; scalable AI architectures are dynamic, distributed, and cloud-native. They can expand horizontally (adding more nodes) or vertically (adding power to existing nodes) to handle demand.
Why do many enterprises struggle to scale AI?
Lack of data strategy, fragmented infrastructure, and poor model monitoring hinder scalability. Enterprises often deploy models without considering autoscaling, load balancing, or latency optimization.
Which industries benefit most from scalable machine learning systems?
Healthcare, e-commerce, logistics, fintech, and education benefit significantly due to fluctuating workloads and real-time decision-making needs.
Can solopreneurs use scalable AI platforms without coding?
Absolutely. Platforms like Kogents.ai offer low-code environments enabling individuals to train, deploy, and scale AI models without deep technical skills.
How do elastic AI systems reduce operational costs?
Elastic systems scale resources automatically, reducing idle compute costs by only using what’s needed. For example, autoscaling GPU clusters can cut expenses by up to 40%.
What’s the role of MLOps in enterprise-scale AI?
MLOps integrates DevOps principles for machine learning, automating deployment, testing, and rollback. It ensures the continuous delivery of scalable AI models across production environments.
Is edge AI part of scalable AI infrastructure?
Yes. Edge AI brings inference closer to the data source, reducing latency. Combined with cloud AI, it creates hybrid scalable AI systems ideal for IoT, manufacturing, and real-time monitoring.
What’s the difference between horizontal and vertical scaling in AI?
Horizontal scaling: Adding more machines (nodes).
Vertical scaling: Adding more power (CPU/GPU) to existing machines. Both are crucial for achieving enterprise-scale AI performance.
How can I start building a scalable AI pipeline today?
Begin with a cloud-native infrastructure (AWS, GCP, or Azure), containerize your models, and adopt CI/CD pipelines. Use tools like Airflow, Kubeflow, or MLflow for orchestration and monitoring.
FAQs
Scalable AI solutions are systems engineered to maintain performance as workloads and data volumes grow. They use cloud computing, distributed architectures, and MLOps to deliver high-performance AI systems capable of serving thousands, or millions, of users simultaneously.
Traditional setups are static and local; scalable AI architectures are dynamic, distributed, and cloud-native. They can expand horizontally (adding more nodes) or vertically (adding power to existing nodes) to handle demand.
Lack of data strategy, fragmented infrastructure, and poor model monitoring hinder scalability. Enterprises often deploy models without considering autoscaling, load balancing, or latency optimization.
Healthcare, e-commerce, logistics, fintech, and education benefit significantly due to fluctuating workloads and real-time decision-making needs.
Absolutely. Platforms like Kogents.ai offer low-code environments enabling individuals to train, deploy, and scale AI models without deep technical skills.
Elastic systems scale resources automatically, reducing idle compute costs by only using what’s needed. For example, autoscaling GPU clusters can cut expenses by up to 40%.
MLOps integrates DevOps principles for machine learning, automating deployment, testing, and rollback. It ensures the continuous delivery of scalable AI models across production environments.
Yes. Edge AI brings inference closer to the data source, reducing latency. Combined with cloud AI, it creates hybrid scalable AI systems ideal for IoT, manufacturing, and real-time monitoring.
Horizontal scaling: Adding more machines (nodes). Vertical scaling: Adding more power (CPU/GPU) to existing machines. Both are crucial for achieving enterprise-scale AI performance.
Begin with a cloud-native infrastructure (AWS, GCP, or Azure), containerize your models, and adopt CI/CD pipelines. Use tools like Airflow, Kubeflow, or MLflow for orchestration and monitoring.
Kogents AI builds intelligent agents for healthcare, education, and enterprises, delivering secure, scalable solutions that streamline workflows and boost efficiency.